
L’autre jour, je vous parlais de l’adoption du nouveau thème GeneratePress sur ce blog (décision dont je me félicite chaque jour, ce qui est une bonne chose soit dit en passant parce que ça me fait du bien de m’auto-valoriser) et je vous ai montré à la fin de l’article à quoi ressemblait Le Blog du Cuk d’avant le changement.
Sauf que quand j’ai voulu le faire, je me suis rendu compte que l’ancien site, eh bien je ne savais plus comment le montrer puisqu’il était remplacé par le nouveau.
J’ai donc appelé mon ami Google à la rescousse et lui ai posé la question « Dis-moi mon ami Goguely, comment fait-on pour retrouver un site web tel qu’il se présentait dans le passé »?
Bon, en réalité, j’ai un peu abrégé, mais c’était à peu près ça,
Le bougre qui ne veut pas se fâcher avec moi m’a répondu dans la seconde (il fait ça aussi avec vous?) et a dressé une liste en tête de laquelle il m’a dirigé vers Internet Archive.
Et je suis arrivé à un endroit absolument génial que, rendez-vous compte, je ne connaissais même pas, honte à moi!
Je me sens un peu comme le gars qui se sentirait tout excité de vous présenter Wikipedia vous voyez, mais ça ne fait rien, je me lance.
Internet Archive, c’est quoi?
Je vous traduis (c’est encore mon ami Google qui m’a aidé, voire qui a tout fait, et il s’en tire plutôt pas mal, le bougre) la description du concept que vous trouverez en langue originale ici:
Internet Archive, une organisation à but non lucratif 501 (c) (3), est en train de construire une bibliothèque numérique de sites Internet et d’autres objets culturels sous forme numérique. À l’instar d’une bibliothèque papier, nous offrons un accès gratuit aux chercheurs, historiens, universitaires, aux personnes incapables de lire les imprimés et au grand public. Notre mission est de fournir un accès universel à toutes les connaissances.
Nous avons commencé en 1996 par l’archivage d’Internet lui-même, un média qui commençait à peine à se développer. Tout comme les journaux, le contenu publié sur le Web était éphémère – mais contrairement aux journaux, personne ne le sauvegardait. Aujourd’hui, nous avons plus de 20 ans d’histoire Web accessibles via la Wayback Machine et nous travaillons avec plus de 625 bibliothèques et d’autres partenaires via notre programme Archive-It pour identifier les pages Web importantes.
Au fur et à mesure que nos archives Web se développaient, notre engagement à fournir des versions numériques d’autres œuvres publiées a augmenté. Aujourd’hui, nos archives contiennent:
• 475 milliards de pages Web (NDLR: 546 en fait, au moment où j’écris ces lignes!)
• 28 millions de livres et de textes
• 14 millions d’enregistrements audio (dont 220’000 concerts en direct )
• 6 millions de vidéos (dont 2 millions de programmes télévisés )
• 3,5 millions d’ images
•580’000 logiciels
Toute personne disposant d’un compte gratuit peut télécharger des fichiers multimédias sur Internet Archive. Nous travaillons avec des milliers de partenaires dans le monde pour enregistrer des copies de leur travail dans des collections spéciales.
Toute personne disposant d’un compte gratuit peut télécharger des fichiers multimédias sur Internet Archive. Nous travaillons avec des milliers de partenaires dans le monde pour enregistrer des copies de leur travail dans des collections spéciales.
Parce que nous sommes une bibliothèque, nous accordons une attention particulière aux livres. Tout le monde n’a pas accès à une bibliothèque publique ou universitaire avec une bonne collection, donc pour offrir un accès universel, nous devons fournir des versions numériques des livres. Nous avons lancé un programme de numérisation des livres en 2005 et aujourd’hui, nous numérisons 1 000 livres par jour dans 28 endroits à travers le monde. Les livres publiés avant 1923 peuvent être téléchargés et des centaines de milliers de livres modernes peuvent être empruntés via notre site Open Library . Certains de nos livres numérisés ne sont disponibles que pour les personnes à mobilité réduite .
Tout comme Internet, la télévision est également un média éphémère. Nous avons commencé à archiver des programmes télévisés à la fin de 2000, et notre premier projet de télévision publique était une archive des nouvelles télévisées entourant les événements du 11 septembre 2001 . En 2009, nous avons commencé à rendre certaines émissions d’actualités télévisées américaines consultables par sous-titres dans nos archives d’actualités télévisées . Ce service permet aux chercheurs et au public d’utiliser la télévision comme une référence citable et partageable.
L’Internet Archive sert des millions de personnes chaque jour et est l’un des 300 meilleurs sites Web au monde. Une seule copie de la collection de la bibliothèque Internet Archive occupe plus de 45 pétaoctets d’espace serveur (et nous stockons au moins 2 copies de tout). Nous sommes financés par des dons , des subventions et en fournissant des services d’archivage Web et de numérisation de livres à nos partenaires. Comme pour la plupart des bibliothèques, nous apprécions la confidentialité de nos clients , nous évitons donc de conserver les adresses IP (Internet Protocol) de nos lecteurs et proposons notre site en protocole https (sécurisé).
Vous pouvez trouver des informations sur nos projets sur notre blog (y compris les annonces importantes ), nous contacter , acheter du swag dans notre magasin et nous suivre sur Twitter et Facebook . Bienvenue à la bibliothèque!
Internet Archive
Comme vous le voyez, les objectifs sont incroyables, et les moyens sont considérables.
Bref, dès que nous ouvrons un compte gratuit, ce que j’ai fait bien sûr, nous avons à faire à une mine d’or, c’est absolument génial.
Regardez d’ailleurs un simple exemple dans le domaine des concerts enregistrés:
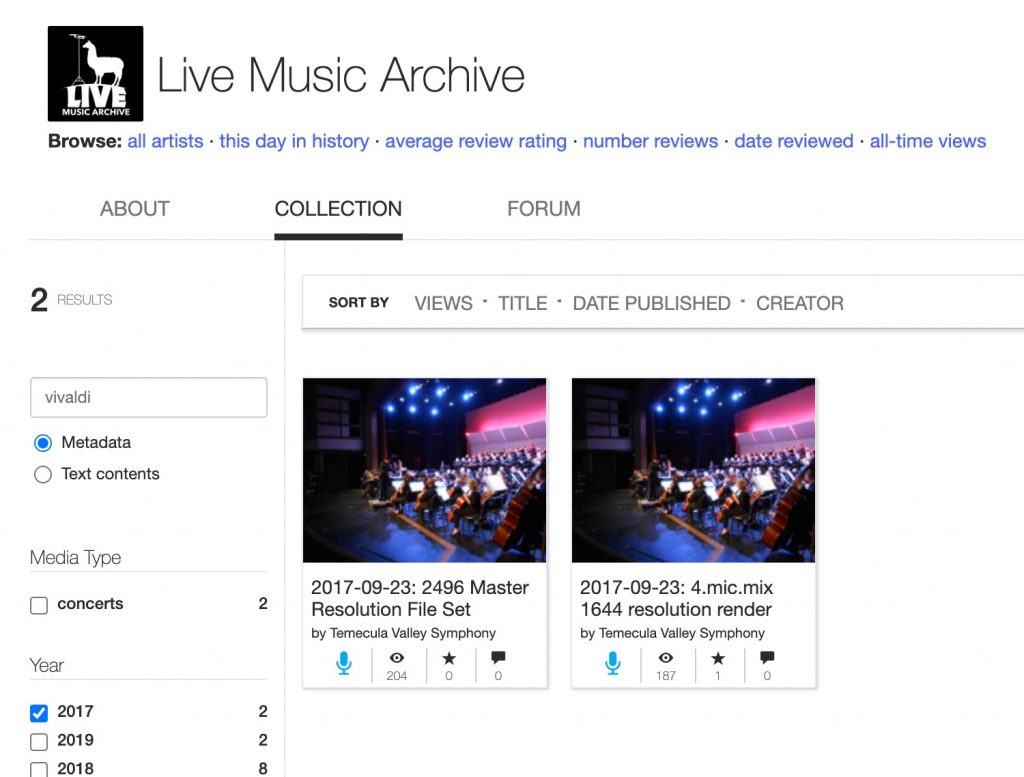
Vous ne les voyez pas entièrement, mais le système de recherche est bien fichu. C’est important, dans ce domaine et la richesse de contenu de cette incroyable base de données.
Et si vous vous créez un compte gratuit (on peut faire un don), vous pouvez télécharger ou au moins lire, voir et écouter tout ce que vous trouvez.
Génial non?
La WayBackMachine, vous reprendrez bien quelques instants de nostalgie?
Je vous disais donc en introduction que je recherchais à quoi pouvait ressembler mon site avant que je change son thème.
Eh bien il suffit:
- d’aller sur le site d’Internet Archive;
- de repérer (c’est facile, c’est tout en haut, on le voit tout de suite) le champ WayBackMachine;

- d’y entrer l’URL du site dont vous voulez connaître l’historique;
- et de regarder le résultat qui s’affiche comme ceci:

Rendez-vous compte! 546 milliards de pages Web enregistrées au fil du temps à l’heure où j’écris ces lignes!
Ici, j’ai pris le site « Cuk.ch » comme exemple.
Malgré le fait que plus rien de nouveau n’y paraisse depuis 2017, il a tout de même continué à être enregistré régulièrement.
Vous constaterez également qu’en 2008 et en 2009, la fréquence d’examens et d’enregistrement d’instantanés a été moins élevée que pendant d’autres années sur ce site.
Il s’est peut-être passé quelque chose cette année-là puisque si je regarde Adobe.ch, je peux faire presque le même constat:
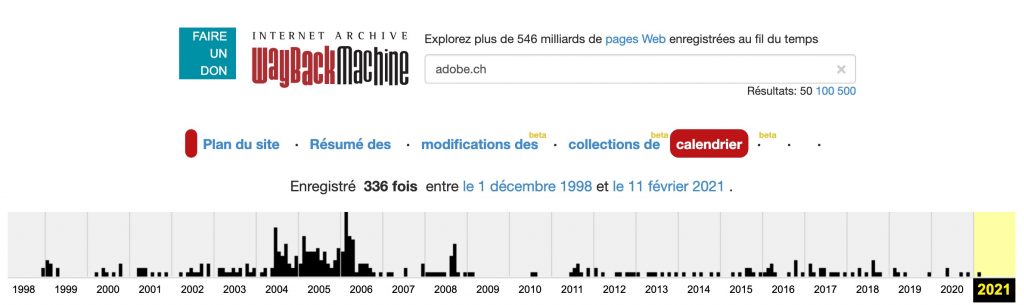
Remarquez que mon constat ne vaut pas grand-chose puisque le site lemonde.fr a été passé en revue quotidiennement par le site en 2009.
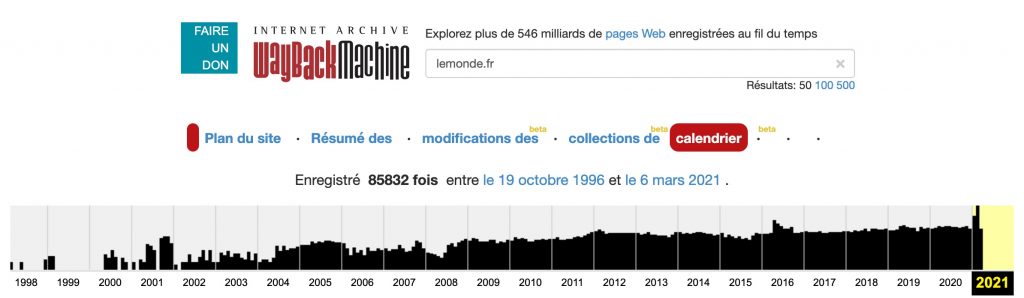
Certainement parce qu’Internet Archive, en tant qu’institution qui tient à enregistrer l’histoire des médias a privilégié l’enregistrement des quotidiens.
Il faut également savoir que les instantanés ne sont disponibles que quelques mois après leur création.
Typiquement, pour le Blog du Cuk, il n’y a rien encore de visible pour 2021.
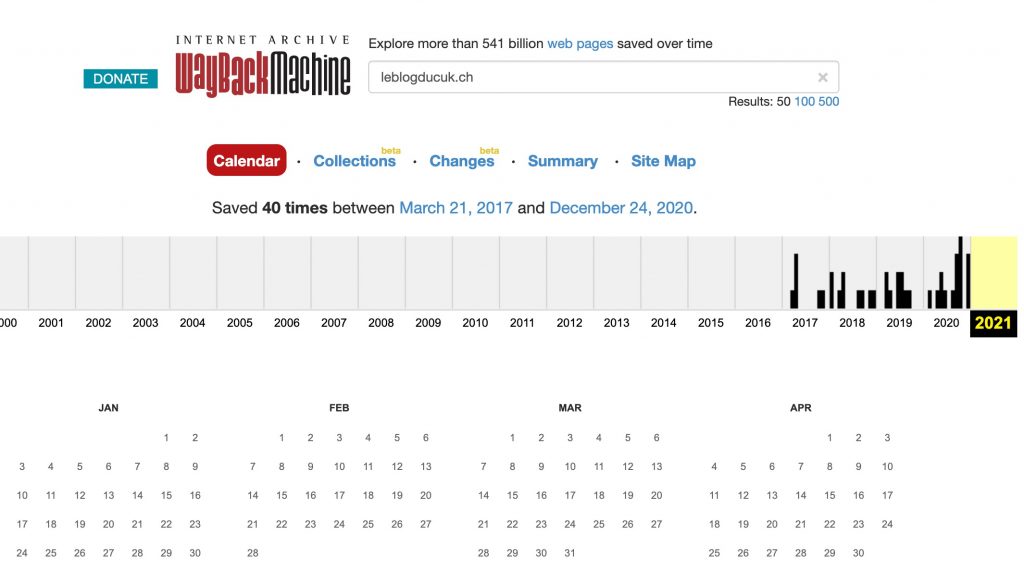
Cela ne signifie pas que le site n’a pas été capturé, mais que simplement, le contenu n’est pas encore à disposition. Visiblement, selon les sites, il faut de quelques semaines à quelques mois pour que le travail effectué par WayBackMachine soit disponible.
Ah! Encore une chose étonnante: le service vous permet de récupérer pour 15$ un site complet, et même, moyennant supplément, de créer un site WordPress plus ou moins équivalent à celui d’origine, le système (ou les humains parce qu’il faut un peu de temps pour obtenir le résultat après commande) cherchant même un thème qui y correspond au mieux.
Au fait, je n’avais pas fini d’expliquer comment retrouver son site, mais c’est tellement simple que j’hésite à le faire.
Allez, oui, je vous montre.
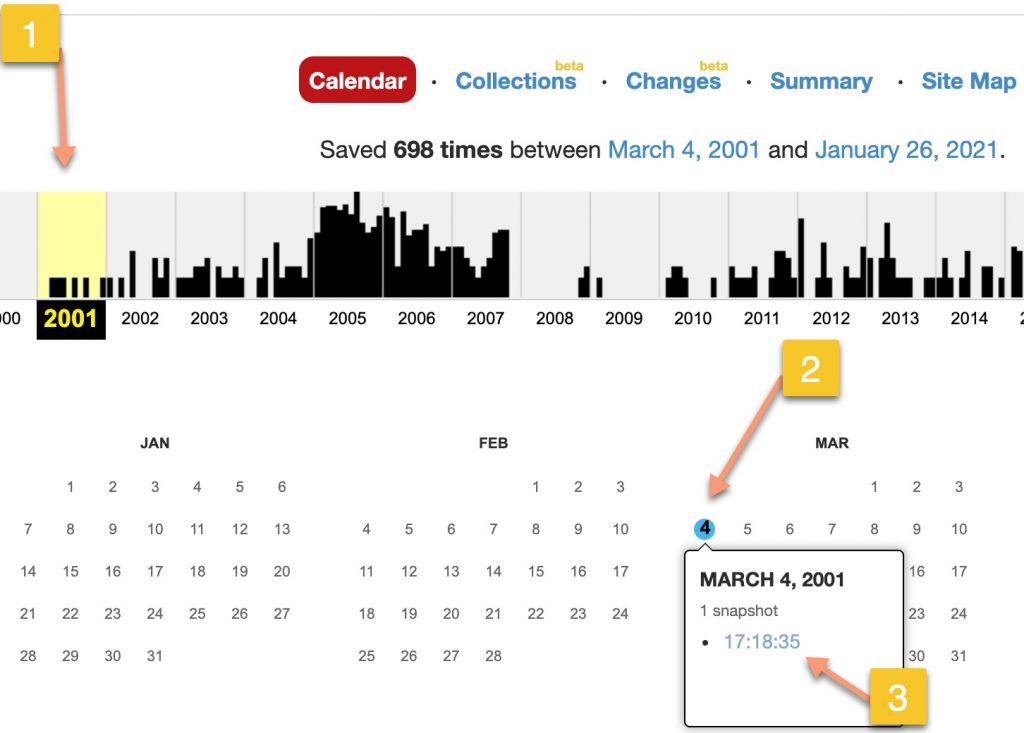
- Vous cliquez sur une année.
- Vous cliquez sur un jour où un instantané a été pris.
- Vous cliquez sur l’heure de l’instantané.
Dans le cas qui caractérise Cuk.ch et l’image ci-dessus, j’obtiens ceci:

C’est la toute première capture de Cuk.ch (je ne parle pas du Blogducuk mais bien de Cuk.ch), bien avant que le site soit devenu celui qu’on connaît.
Un peu plus tard, la première version du site avec ses humeurs, ses tests, ça donnait ça:
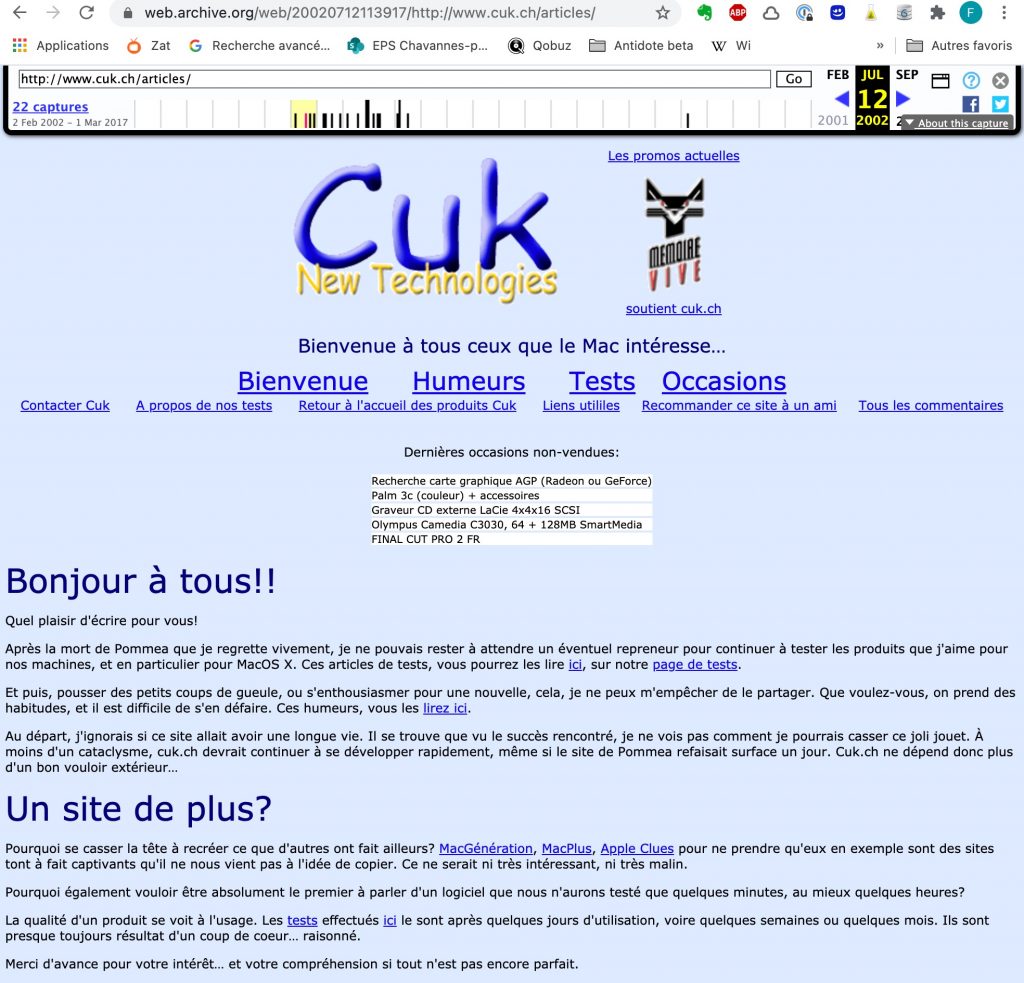
Bref, je ne vais pas vous refaire l’histoire de Cuk.ch, vous pouvez d’ailleurs la lire ici, lorsque Noé avait écrit un article la relatant lors du passage en v4.
Heureusement, nous avions bien progressé!
Dernière chose: jusqu’à dix niveaux de liens sont présents dans un instantané, liens cliquables et tout et tout, mais il faut savoir que parfois, certaines images sont manquantes ou certains liens sont cassés. C’est plutôt normal.
Sinon, vous auriez des petites pépites à nous montrer dans l’histoire des sites Web, grâce à Internet Archives?
Je suis preneur en commentaires!
En savoir plus sur Le Blog du Cuk
Subscribe to get the latest posts sent to your email.




























Bonsoir François et tous !
Sur ce sujet Internet Archive, Xavier de la Porte a fait un épisode de podcast passionnant.
Archiver le web : une entreprise folle et merveilleuse, avec Valérie Schafer (franceinter.fr)
Précipitez-vous, chanceux qui ne l’avez pas encore écouté.
Et si vous continuez sur d’autres épisodes de ce podcast consacrés à d’autres thèmes, vous ne serez pas déçus.
En commençant par le premier épisode qui est une petite introduction intelligente et stimulante aux restes des épisodes
Sébastien
Belle découverte, merci !!! Voilà encore un endroit où je vais aller passer des heures et raccourcir mes déjà courtes nuits.
Le traducteur Google est très bien, mais il bégaie un peu (ou alors c’est le copieur-colleur?) : il y a deux fois le paragraphe 5, juste après l’inventaire des milliards, millions et milliers de pages archivées.
Merci de cette découverte qui raconte … l’histoire de l’histoire
Apple 22 octobre 1996.
France Inter 19 avril 2005.
Le Monde 19 décembre 1996.
Adobe 22 octobre 1996.
Voilà, c’est ma contribution du jour… Pas très original, j’en conviens.
Merci beaucoup Sébastien, je vais l’écouter.
Ah mais c’est incroyable!
Apple en 1996 n’était pas vraiment brillant, quoique, à l’époque, ça dût être le top du top.
Idem pour les autres.
Sympa hein, de se promener dans tout ça!:-)
Quelque part oui, c’est du deuxième niveau quand on y réfléchit.
Oui, c’est rigolo et ça montre aussi le chemin parcouru en à peine 25 ans.
Je pense parfois à ma grand-mère, née en 1907 – 118 ans seulement après la Révolution Française – et décédée en 1984 (année du film publicitaire de Ridley Scott pour le Macintosh), elle a vu arriver les voitures, la traction électrique des trams et des trains, la radio, la TV, les vols passagers de masse, les premières centrales vapeur pour le repassage (plus jeune, elle faisait chauffer des fers sur la plaque du poêle à charbon, lequel charbon montait par seaux de la cave au 3ème étage à bras de femme…), elle a vu Armstrong marcher sur la lune, etc… C’était une femme très simple, une ouvrière, et elle était passée à travers deux guerres et tous ces changements, je n’ose pas dire ces progrès, comme si de rien n’était.
Que penseront de nos vies nos petits-enfants ?
Très intéressant!
En amateur de « vieilleries », comme tu me connais, je connaissais plutôt Internet Archive pour aller y écouter des 78 tours ou des concerts au bar ou à la ferme du coin.
Comme ici.
Ou aller regarder des home movies en 8 mm ou des documentaires des années 40 sur les joies de l’automatisation et de la robotisation.
Comme là.
Je me le demande souvent.
C’est super ton film!
Il y a des trucs qu’on utilise aujourd’hui, comme le distributeur de croquettes pour chiens ou chats! Et le robot arroseur de fleurs, trop top!?
Très intéressant. Et, en effet, comment archiver ce qui change sans arrêt ?
J’ai utilisé de nombreuses fois ce site internet, pour me permettre de retrouver d’anciens sites disparus, ou alors parfois quand sur des forums il y avait une panne avec perte de données, ça a permis de retrouver des fils de discussion et d’en sauvegarder une partie !
En effet, ce doit être utile dans ce genre de situations, merci.